This is a two part workshop for UCLA DataFest competitors on how to organize a data analytics project with Python.

Weeknights mean Jeopardy in my household. I’ll watch the show with anyone that’s willing to listen as I mutter answers at a television screen while Alex Trebek asks challenging trivia questions. Jeopardy has been a central feature of my life, bonding with my Dad over dinner or competing with college roommates to see who is the “smartest”.
The show is known for its structured and professional manner, where contestants are cordial with one another, and everyone demonstrates a sort of deference to the show and its now legendary host. After the first commercial break, however, all contestants are given a chance to discuss something interesting about themselves. This is where, in my opinion, anyone who is a fan of the Bachelor gets a taste of their favorite snack: human judgement. It’s fun watching contestants talk about being mistaken for Nicolas Cage in Mexico, or tell embarrassing stories about coaching Quidditch teams (these are real examples!)
As an exercise in exemplifying how to conduct an independent data analytics project, I thought it would be fun to look at anyone but the Champions. More specifically, I want to take a deep dive into the types of people that make it onto the show, and what aspect of their lives they think is worth discussing in front of a live audience. From a data perspective, can we simulate the contestant’s fun facts and create a Jeopardy Watson with its own personality?
Part 1: Capturing The Data
We can collect information on Jeopardy contestants from the Official Jeopardy Archive. The Jeopardy Archive collects and maintains all details related to the show, including each contestant’s name, occupation, hometown, number of games won, cash winnings, and more. Using the BeautifulSoup library in Python 3.7, we can scrape the website for these variables and build a data set of details for each contestant on each show.
Web-Scrape the Jeopardy Archive
Reviewing an individual game on the archive, we see the page stores player’s details at the top of each game, and their total scores throughout each of the rounds, displaying their total and final scores at the end at the bottom.
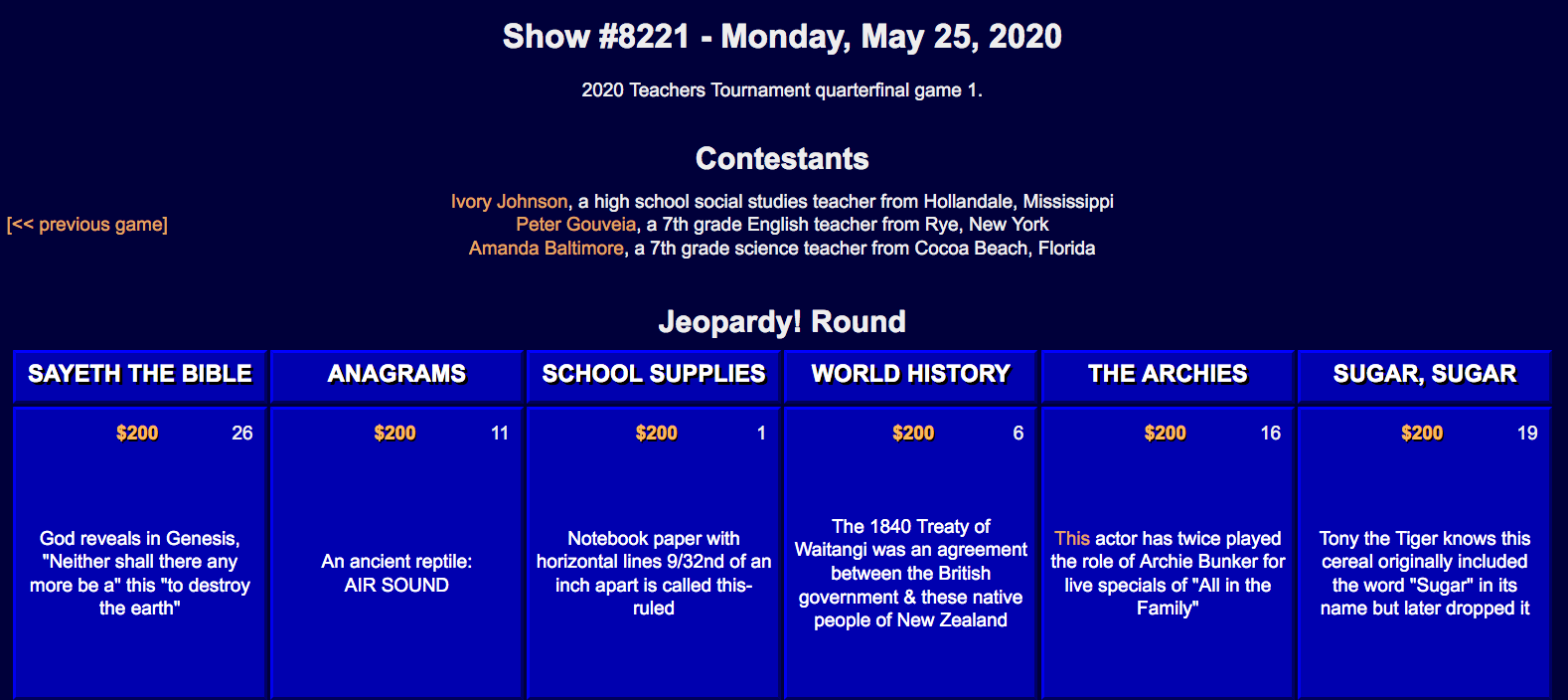
To capture this information, we can put together a function that will iterate through the pages to pull these out for each game played. We will start on game ID 6389, and iterate back in time to capture a specified number of games.
# Set-Up
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup #main web-scraping package
import requests # allows you to send https requests
import pandas as pd # for manipulating data into data frames
import re # regular expressions package
# Define Function that sets a game ID and number of pages to extract from the jeopardy archive
def jep_scraper(game_id = 6389, num_pages_to_extract = 300):
# initialize variables
index = 0
new_game_id = 0
output = []
error_catalog = []
archive_link = "http://www.j-archive.com/showgame.php?game_id="
jeopardy_archive_link = archive_link + str(game_id)
while index < num_pages_to_extract:
# get page, timeout set to 5 seconds
page_response = requests.get(jeopardy_archive_link, timeout=5)
# confirm no error with pull
try:
page_response.raise_for_status()
pass
except:
print("HTML ERROR CODE: " + str(page_response.status_code))
page_content = BeautifulSoup(page_response.content, "html.parser")
# create empty variables to fill
anecdotes = []
final_scores = []
names = []
show_info1 = []
show_info2 = []
show_info3 = []
#title date
title_date = page_content.find_all('title')[0].text
# iterate through three contestants
for j in range(0, 3):
#Find all anecdotes for contestants
paragraphs = page_content.find_all("p")[j].text
# Final all final scores for contestants
try:
table1 = page_content.find_all(lambda tag: tag.name == 'td' and
(tag.get('class') == ['score_positive']
or
tag.get('class') == ['score_negative']
# some scores can be negative!! See 5913
)
)[9:12][j].text
pass
except IndexError:
print("Error 1 @ Game ID:" + str(new_game_id))
# error output - used to locate mismatched fields
error_catalog.append(jeopardy_archive_link)
# store links from archive (typically special events)
#extract player names and details
try:
table2 = page_content.find_all(lambda tag: tag.name == 'td' and
tag.get('class') == ['score_player_nickname'])[j].text
pass
except IndexError:
print("Error 2 @ Game ID:" + str(new_game_id))
# error output - used to locate mismatched fields
error_catalog.append(jeopardy_archive_link)
# store links from archive (typically special events)
try:
table3 = page_content.find_all(lambda tag: tag.name == 'td' and
tag.get('class') == ['score_remarks'])[j].text
pass
except IndexError:
print("Error 3 @ Game ID:" + str(new_game_id))
# error output - used to locate mismatched fields
error_catalog.append(jeopardy_archive_link)
# store links from archive (typically special events)
#append these player details together
anecdotes.append(paragraphs)
final_scores.append(table1)
names.append(table2)
# reorder and correct data (anecdotes go 2 1 0 / names and scores go 0 1 2 )
show_info1.extend([names[0],anecdotes[2],final_scores[0],title_date])
show_info2.extend([names[1],anecdotes[1],final_scores[1],title_date])
show_info3.extend([names[2],anecdotes[0],final_scores[2],title_date])
#add to final output file
output.append(show_info1)
output.append(show_info2)
output.append(show_info3)
#create link to next page by creating previous page number
new_game_id = page_content.find_all(lambda tag: tag.name == 'a' and
tag.get('href') and
tag.text == "[<< previous game]")
#print(new_game_id)
#[<a href="showgame.php?game_id=6388">[<< previous game]</a>]
# WE WANT THE GAME ID ----------^^^^
new_game_id = re.findall(r'\d+', str(new_game_id[0]))[0]
# USE REGEX TO CAPTURE JUST DIGITS
# create next page link
jeopardy_archive_link = archive_link + new_game_id
jeopardy_archive_link
#update iterator
index = index + 1
#return items
return output, error_catalog
The function works by extracting the title of each game, and assigning it to each player, along with their scores and details. One of the tricky aspects with this data is that the players are named right to left, but their data is recorded left to right. This is a simple problem but one that can isn’t obvious without cross checking some live game footage.
Once a game’s information has been scraped, the function simply calls the previous page’s link, and loops continuously until it finds the predetermined number of game details. Any errors found are stored in a separate output list, for review once the task is complete. These errors highlight some of the different game types that jeopardy tends to host, such as the Celebrity or Team tournaments (i.e. Game ID 6223 )
Extract Tweets from @CoolJepStories

But what about those “fun facts” that players share after the first commercial break? These are not recorded at all on the archive, and there is next to no centralized database for these anywhere online.
To get a sense of these anecdotes, we rely on the work of Chad Mosher, as there are no episode transcripts easily available online 1. Chad ran the @CoolJeopardyStories account from February 11th, 2014 to July 26th, 2019, where he created tweet length version’s of each show contestant’s story. While these transcription aren’t perfect representations, they get to the meat of the stories and will work for our purposes.
First, we set up a Twitter developer account to extract data from the site. Once we have credentials, we can build a simple script using the Tweepy package in Python to extract tweets from specified accounts.
# -*- coding: utf-8 -*-
import tweepy
import pandas as pd
# fill these in with your own twitter developer information
consumer_key= '###############################'
consumer_secret= '###############################'
access_key = '###############################'
access_secret= '###############################'
#User ID
userID = "@CoolJepStories"
# Authorization to consumer key and consumer secret
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
# Access to user's access key and access secret
auth.set_access_token(access_key, access_secret)
# Calling api
api = tweepy.API(auth)
Twitter contains plenty of documentation on how to use their API, as well as other resources online. We first want to specify the number of tweets to call from the user account, as well as they type of tweets. In this case, we only need actual tweets from the account (no retweets.)
# 1750 tweets to be extracted
number_of_tweets=1750
tweets = api.user_timeline(screen_name=userID, count = number_of_tweets,
include_rts = False, tweet_mode="extended")
all_tweets = []
all_tweets.extend(tweets)
oldest_id = tweets[-1].id
while True:
tweets = api.user_timeline(screen_name=userID,
count=200, # max allowed count
include_rts = False,
max_id = oldest_id - 1,
# Necessary to keep full_text
# otherwise only the first 140 words are extracted
tweet_mode = 'extended'
)
if len(tweets) == 0:
break
oldest_id = tweets[-1].id
all_tweets.extend(tweets)
print('N of tweets downloaded till now {}'.format(len(all_tweets)))
We can then continuously call chunks of these tweets, 200 at a time in this case due to limits on the API. Once collected, we use Pandas to convert them to a Dataframe, and quickly save them to a csv to avoid having to run anything again.
#transform the tweets into an array that will populate the csv
outtweets = [[tweet.id_str,
tweet.created_at,
tweet.favorite_count,
tweet.retweet_count,
tweet.full_text.encode("utf-8").decode("utf-8")]
for idx,tweet in enumerate(all_tweets)]
df = pd.DataFrame(outtweets,columns=["id","created_at","favorite_count","retweet_count", "text"])
df.to_csv('%s_tweets.csv' % userID,index=False)
After some additional data cleaning and string extraction, we can merge these datasets together on their respective player IDs and date fields to create a full data set of contestant details. The final dataset for our analysis contains 1,971 contestants playing in games ranging from October 24th, 2010 to July 26th, 2019.
Read Part 2 for the analysis of the contestant data!
Data
Code
Footnotes + Citations
-
If you work for Jeopardy or NBC, I would love access to transcripts from the show to analyze! ↩